Slots to the (Wallet) Rescue
How to save more than 17x in query cost.

At Huq Industries, we collect and process 30 billions geo-events a month from more than 8 million devices. At the time of writing we collected and enriched more than 300 billions events all stored in BigQuery table for a total of about 85 TB.
In this blog post, I will demonstrate how we reduced the cost a single expensive job from more than 425$ using on-demand pricing (5$/TB) to just 25$ using flat-rate pricing.
Usually, flat-rate pricing is generally used when you want predictable costs and have a stable and continue slots usage. However, flat-rate pricing can be leveraged also to reduce the cost of even a single job alone.
In this post, I will use a real-world scenario from one of our clients to show how flat-rate pricing helped us saving lots of money when performing this very data-intensive job.
For a more detailed explanation of what are and how BigQuery slots work refer to the official docs. To put it simply, you can think to a BigQuery slot as:
A virtual CPU used by BigQuery to execute SQL queries.
BigQuery Slots Commitment and Reservation
Before we start using BigQuery flat-rate, we need to have a quick introduction on how to provision and allocate slots reservations. If you already have familiarity with this slots commitment and reservation feel free to skip this section and jump directly to the next part.
We will follow the Google best practice to set up the environment to use slots reservations. First, we create a new GCP project to only manage slots and reservation. Then, using the “Reservation” menu from te BigQuery UI, we buy a Flex slots commitment. This type of commitment is more expensive than monthly or annual ones, but it can be cancelled any time after 60 seconds. Tip: Use the right-hand side widget to get an estimation of hourly/monthly cost of your commitment.
Now that we have available slots, we need to create a reservation. You can grant to a reservation as many slots you want (up to the number you bought) and you can create as many reservations you like. Slots not assigned to any reservation go in the default one. In case they are idle, they can be used by any reservation.
The last step is to create an assignment by assigning a reservation to one of our project/folder. Now we are ready to run our job using flat-rate pricing instead of on-demand.
The Scenario
One of our client wants to run analytics on our entire events history, however, they have some specific matching criteria for qualifying an event. Therefore, the actual data they need is much smaller than our full history table. Due to the custom nature of the filtering logic, we had no other option than running a query to select all the qualify events. Below, you can find a mock query that could be used to generate the client dataset.
Start Small
For simplicity, I will calculate the cost by multiplying the reservation cost per minute and the query duration in minutes. This makes the estimations slightly lower than the actual cost because slots are paid also when they are idle. However, for our purpose the difference is negligible.
Firstly, to test the feasibility of this approach, I run some experiments with a smaller dataset (just a month of data ~6.5 TB).
The table below shows durations and costs for the job executed using on-demand and using different amount of slots.
| Duration (min) | Cost($) | Improvement Factor | |
|---|---|---|---|
| On-Demand | 2:26 | 32.5 | - |
| 500 Slots | 5:18 | 1.6 | 20x |
| 1,000 Slots | 3:05 | 2 | 16x |
| 2,000 Slots | 1:43 | 2.7 | 12x |
| 4,000 Slots | 1:06 | 2.9 | 11x |
As you can see from the results, using flat-rate pricing reduced the costs significantly. In fact, the fewer slots we use, the cheaper the job becomes. On the down side, it needs more time to complete, but this is expected. The interesting results is that the 2,000 and 4,000 slots tests showed not only a similar decrease in cost, but also and improvement in performance. This looks like a win-win situation!!! We need to remember that this analysis is valid for our non complex query and it might yield very different results for more complex jobs and workloads. I will present different scenarios and their analysis in the following blog posts.
Let’s go a bit more in the details of the experiments results.
I used bqvisualiser to visualize the job progress and estimation of slots usage during execution. The top part of the graph shows the units of work that BigQuery needs to perform to complete the query. The bottom part of the graph shows the estimated used slots at a certain time during the query execution.
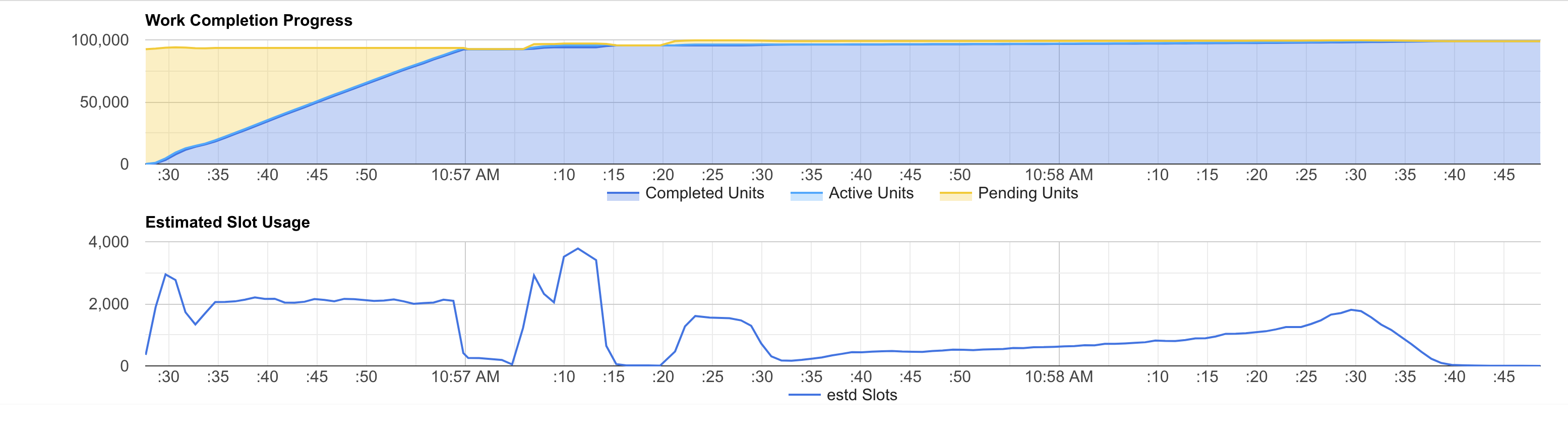
When using on-demand pricing our slots usage profile shows that it cruises around 2,000 slots, but sometimes it bursts to 4,000 slots (however, it often uses fewer slots). This happens because when using on-demand pricing, the available slots are (loosely) “capped” to 2,000 slots per project. However, projects might access to more slots in burst from time to time.
The slots usage profile radically change when running the query under a reservation. It is clear that the query fully utilizes the available slots for almost 100% of the execution time. This is particularly true for the 500 slots test:
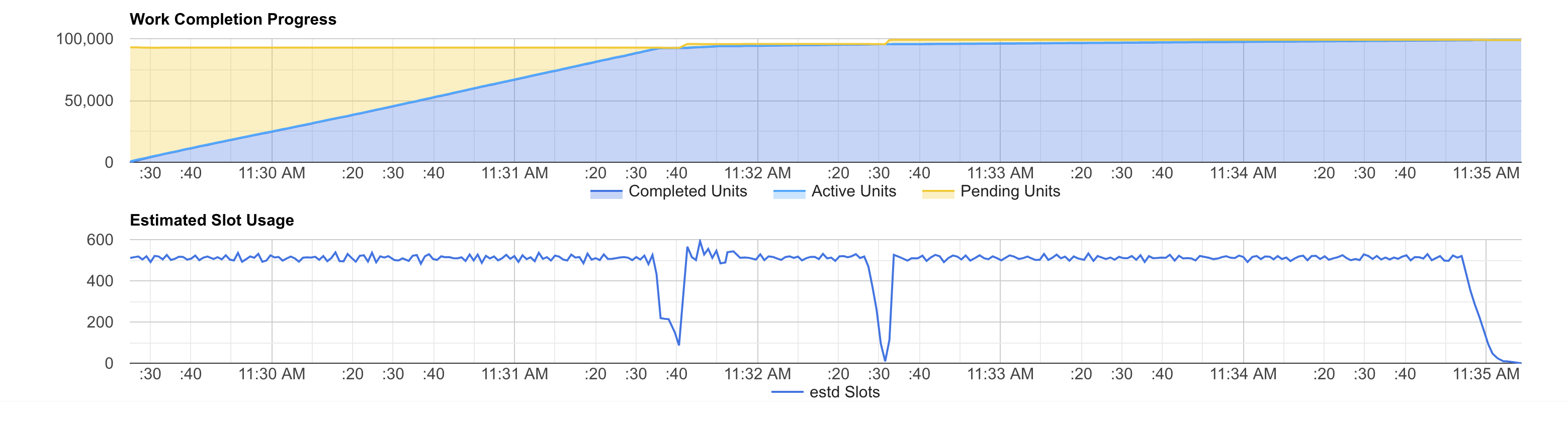
It is clear that this query uses all the available slots except for 3 parts: the first 2 dips and the tail. The first 2 dips are linked to a repartition and a consequent re-aggregation stages. Meanwhile, the tail is due to some workers needing more time to complete their writes.
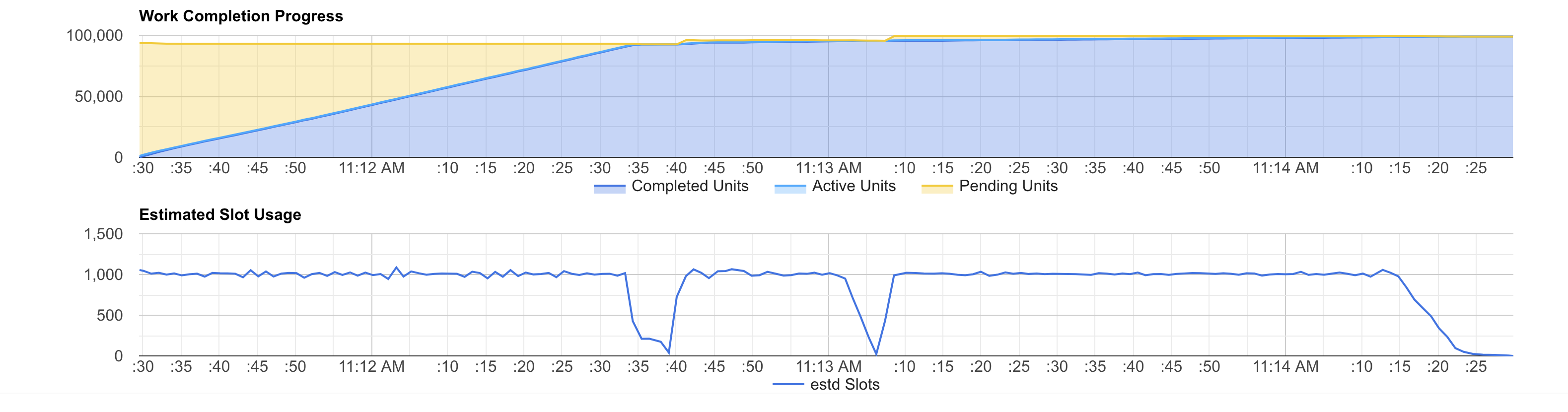
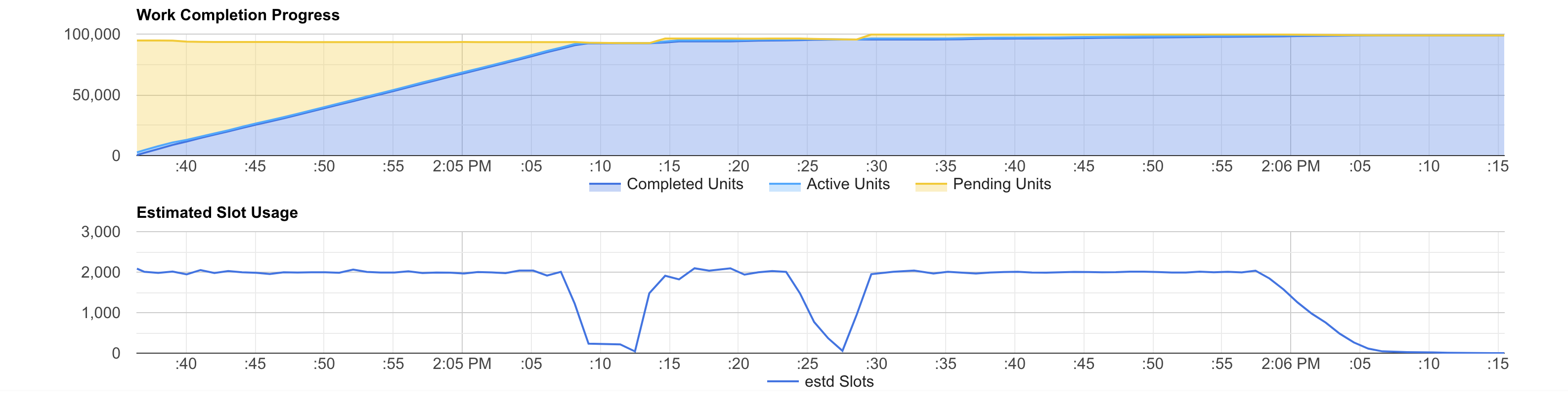
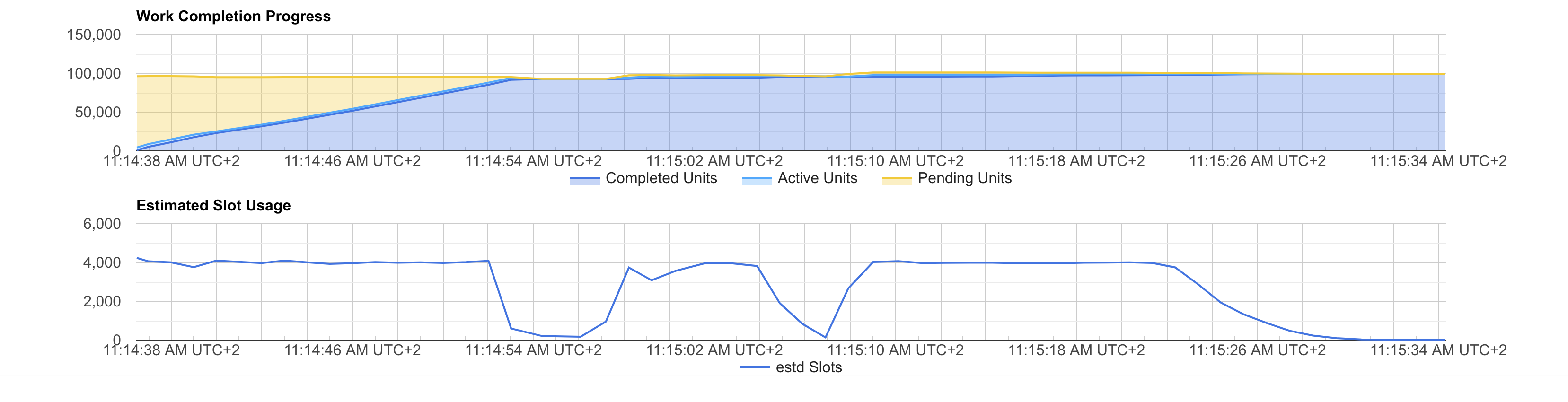
In general, more slots make the job faster (as long as BigQuery can divide the job in enough work units). However, you can see that the job parts that do not fully utilise a small slots reservation will not use more slots even when the reservation is larger.
Moreover, the final cost is consistently reduced, even if we end up paying for idling slots.
Go Big
Now let’s see how the full job performed. This time, I will not run the job using on-demand pricing for obvious reasons 💸💸💸💸💸.
| Duration (min) | Cost($) | Improvement Factor | |
|---|---|---|---|
| On-Demand | – | 425 | - |
| 500 Slots | 75 | 25 | 17x |
| 1,000 Slots | 40 | 25 | 17x |
| 2,000 Slots | 25 | 33 | 13x |
| 4,000 Slots | 14 | 37 | 11x |
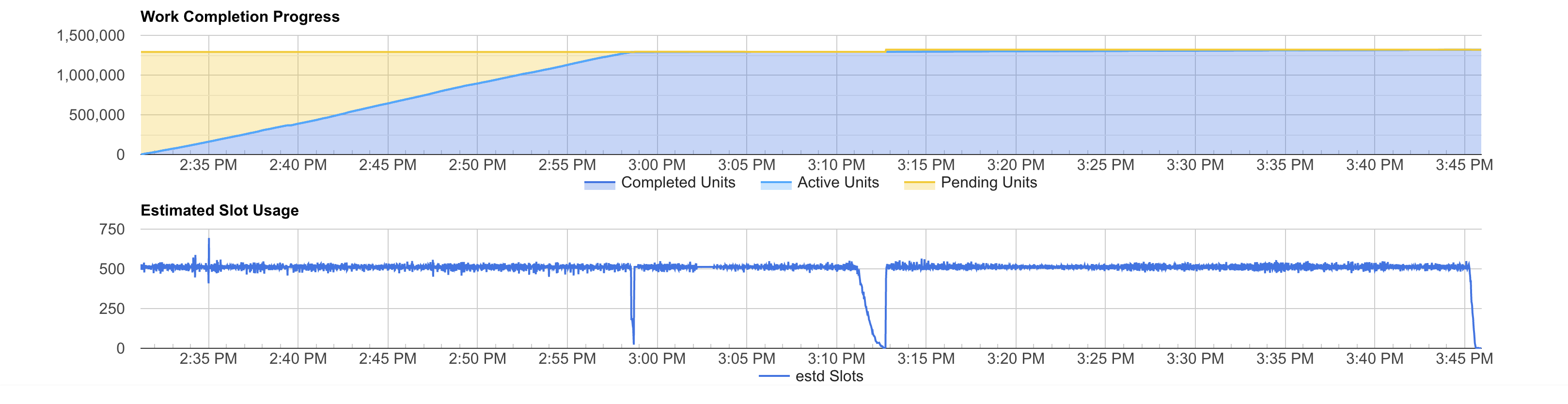
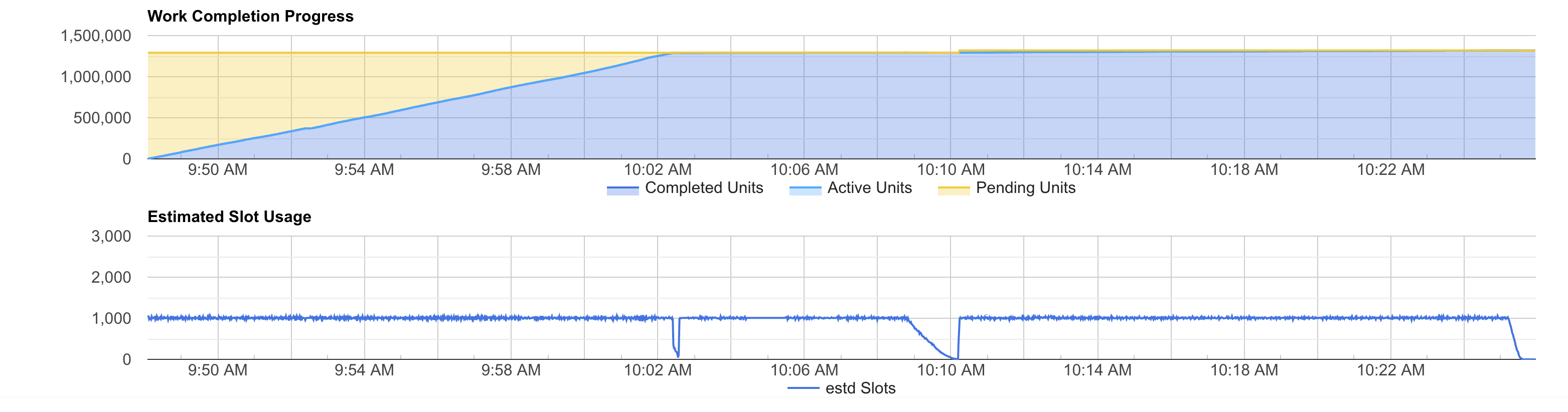
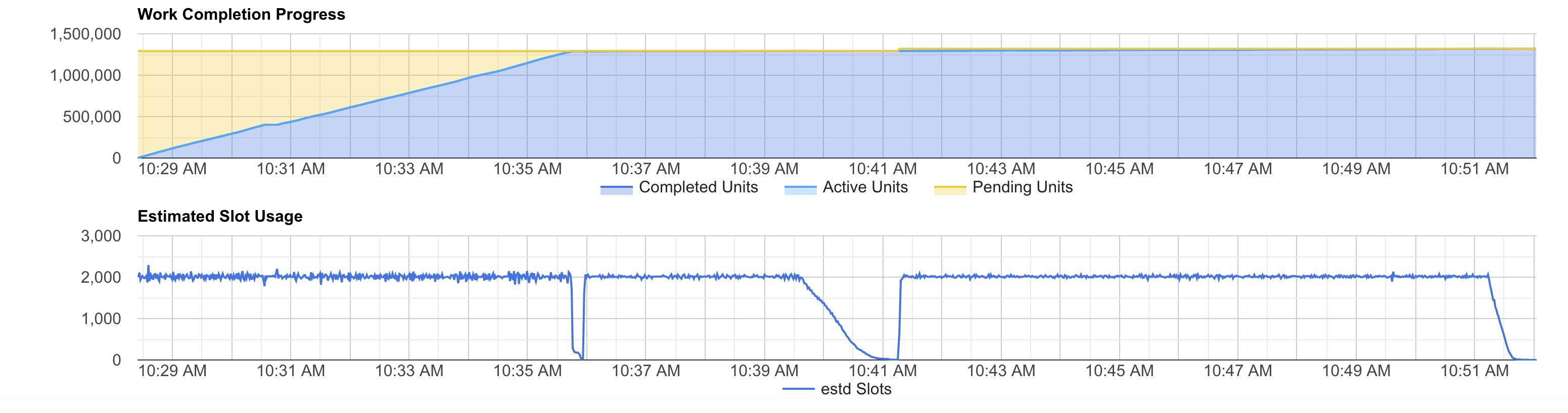
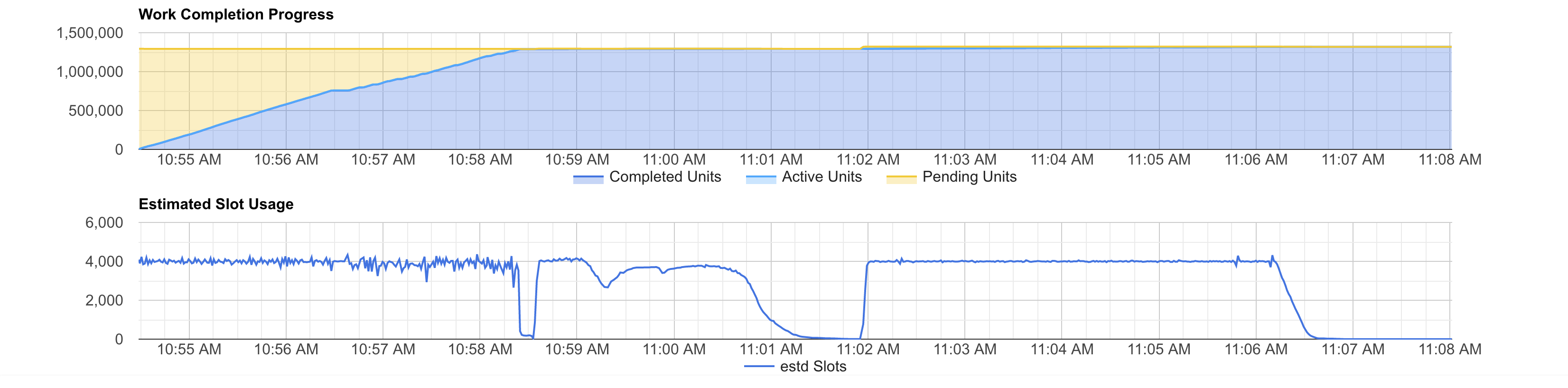
We can see the same pattern in the estimated slots usage graph. In fact, you can see the same the 2 dips and the tail.
In our case, the query has only a few and short dips and tail. So, we could continue improving performance by simply buying more slots. You can see that when we test 4,000 slots the job complete faster than with 2,000, but it costs more. This is because the time we save adding more slots is not enough to compensate the idle slots time.
Conclusion
In conclusion, flat-rate pricing proved to be enormously beneficial to reduce the cost of our data-intensive job. However, beforehand it can be tricky to decide when to use flat-rate or on-demand pricing for a job. Intuitively, we can say that a good candidate for flat-rate pricing is a job that:
- Will scan lots of data (it will cost lots of money using on-demand pricing).
- Has a very consistent usage of slots during its execution time.
- The job doesn’t have strict time completion requirements.
Stay tuned for more in depth experiments and analysis on BigQuery slots and different workloads evaluation.
Follow or contact me on Twitter for more stories about data, infrastructure, and automation.