BigQuery Geography Clustering
Improve your geospatial analytics performance in minutes.
The BigQuery team rolled out support for geography type a while ago and they have never stopped improving performances and Geographic Information System functions (GIS). This allows users to run complex geo-spatial analytics directly in BigQuery harnessing all its power, simplicity, and reliability.
Hold on your keyboard (or your screen if you are reading this on a mobile device).
Now you can cluster tables using a geography column. Say what!!!!
This is game changing for users working heavily with geodata. By clustering your table on a geography column, BigQuery can reduce the amount of data that needs to read to serve the query. This makes queries cheaper and run faster when filtering on clustering column.
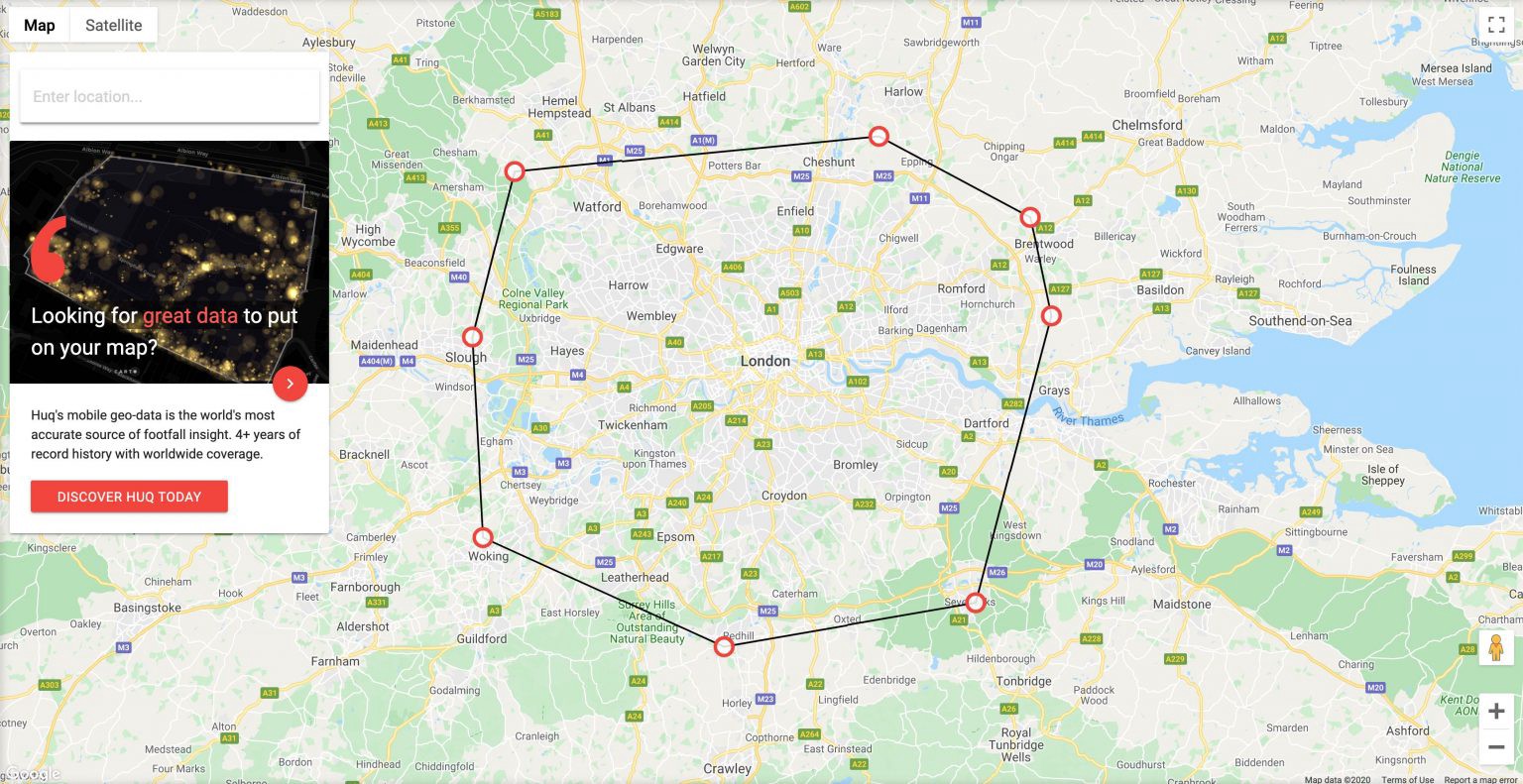
Let’s see the benefits of clustering table using geography column with an example. We will use one of the great public datasets curated by Felipe Hoffa. We will use the weather_gsod specifically the two tables all and all_geoclustered.
Let’s say that we want the all-time minimum and maximum temperature within the Greater London area for each station. Our query will look like this:
Results:
name min_temp max_temp
ST JAMES PARK 26.3 83.2
KENLEY AIRFIELD 18.0 82.8
HEATHROW 18.6 83.4
CITY 22.3 92.2
BLACKWALL 37.0 62.2
NORTHOLT 18.4 84.1
BIGGIN HILL 15.5 90.3
PURLEY OAKS 23.0 81.7
LEAVESDEN 22.3 89.1
LONDON WEA CENTER 20.0 85.2
KEW-IN-LONDON 23.3 82.4
This query reads 9.02GB of data. Now let’s see how the same query perform on the clustered table:
The result is obviously the same but, this time, BigQuery reads just 98.97MB of the data!!! So switching to the geo clustered table made this query almost 100 times cheaper. Do you want to try other locations and test the differences yourself? You can use Huq Industries GisMap tool to quickly draw and export polygons in various formats.