Google Cloud Composer: Overcoming The Short-living Tasks Problem
Improving efficient in executing millions of short living tasks.
Introduction
Google Cloud Composer is Google Cloud Platform product that helps you manage complex workflows with ease.
It is built on top of Apache Airflow and is a fully managed service that leverages other GCP products like Cloud SQL, GCS, Kubernetes Engine, Stackdriver, Cloud SQL and Identity Aware Proxies.
You don’t have to worry about provisioning and dev-ops, so you can focus on your core business logic and let Google take care of the rest. With Airflow it’s easy to create, schedule, and monitor pipelines that span both cloud and on-premises data centres. With a vast selection of “Operators”, you can define pipelines natively in Python with just a few lines of code, and connect to several cloud providers or on-premises instances. If you don’t find the operator that fits your needs, it’s incredibly easy to create your own and import it. If you want to learn more about Apache Airflow, refer to the official docs.
Running short-living tasks
Airflow is a great tool, but as is often the case with high-level tools,
it can introduce overheads when compared to lower-level implementations of the same operation.
To get an idea of the overhead that Airflow could introduce,
we can analyse the health-check example and run it on a Cloud Composer instance.
The health-check DAG consists of a single bash operator that executes a simple command ( echo ENVIRONMENT_NAME).
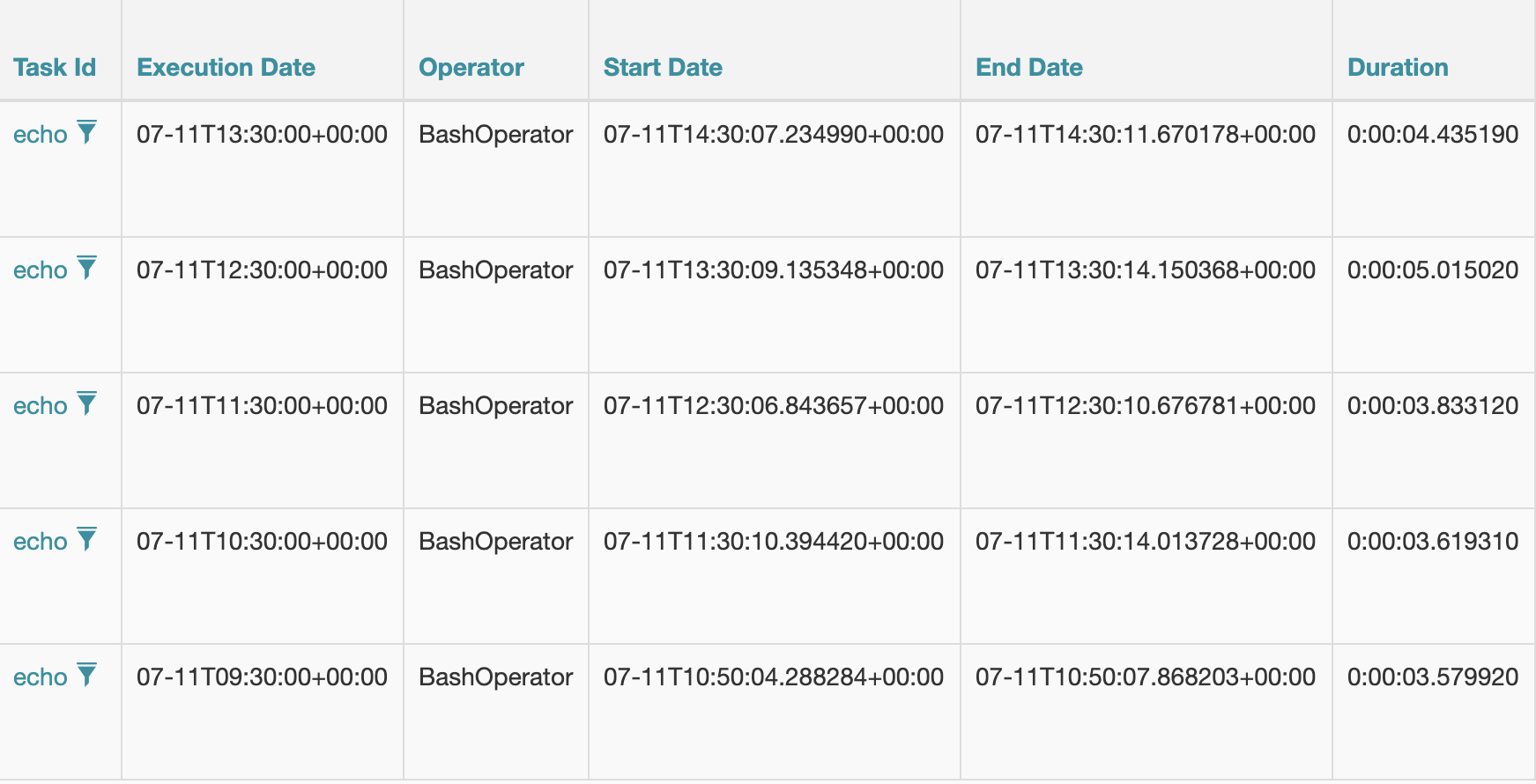
The following screenshot shows 5 runs of this workflow and returns run-times of 3.6 and 5 seconds.
As this scale linearly across multiple invocations, the lag becomes a real problem if - like us - you’re running thousands of them.
To validate this, let’s also measure how much time the same command run for if executed directly from the command line.
# time echo my-awesome-string
real 0m0.000s
user 0m0.000s
sys 0m0.000s
As expected echo is blazing fast - and even trying to measure its execution time with the standard implementation of time does not cut it.
We could recompile the kernel with CONFIG_HIGH_RES_TIMERS=y - but who has time for that!
So to find out, let’s use date with nanosecond precision (keep in mind that in this way the measure will be slightly overestimated).
# date +"%9N"; echo my-awesome-string ; date +"%9N"
571368370
my-awesome-string
573152179
This output is the decimal part of the date-stamp expressed in nanoseconds, so to get the elapsed time the equation is:
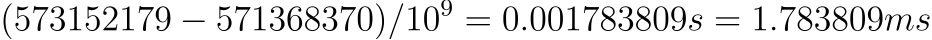
A more realistic, yet simple pipeline
Now that the results are in, it is pretty clear that the actual time needed to run the echo command is irrelevant
compared with the duration time of the corresponding Airflow task.
So in this case, we can say that Airflow introduces an overhead of about 4 seconds.
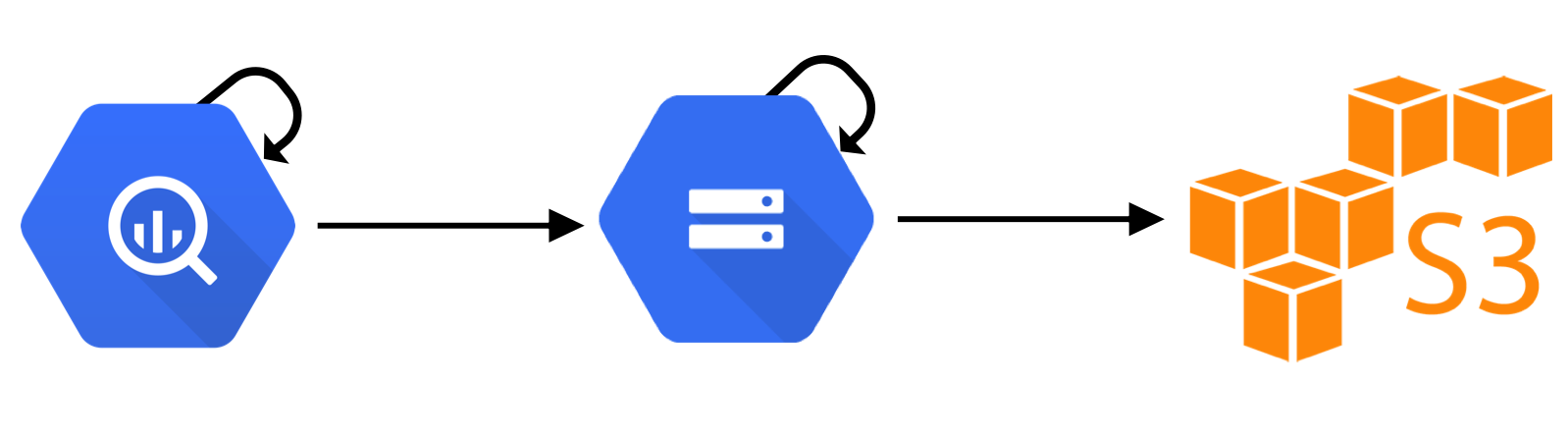
Let’s apply these findings to a more real-world example. Let’s imagine we have a pipeline made of 4 tasks:
- Run a query on BigQuery using the BigQuery operator.
- Export the data to GCS.
- Compose the exported file into a single file.
- Copy the composed file to S3.
In our world, this pipeline runs daily for each country (of which we cover almost 250), which results in 1,000 tasks per daily run. It takes just a few minutes to execute this operation via a simple bash script because each operation runs for just a few seconds. Using Airflow however, this pipeline takes about an hour to complete. When running a backfill job over 3 years of data across 3 different instances of this pipeline, we end up with more than 3 millions tasks to execute, and having so many tasks to manage at the same time creates an avalanche effect. This overwhelms the system and causes problems in getting tasks to schedule, queue, and run.
To achieve our aim while invoking fewer tasks, we accepted a reduction in the granularity of execution and parallelism but maintained the automation capabilities offered by Airflow. We were able to tune this developing an Airflow plugin called Chains, which can be found in the airflow-plugins repository.
NB. If you have built a custom operator or plugins that you want to share, you can do that by submitting a PR to that repository.
The Chain Airflow plugin
The Chain plugin offers 2 operators that you can use to chain together a set of operations:
BigQueryChainOperatorBigQueryToCloudStorageChainOperator
These operators are based on the corresponding official ones ( BigQueryOperator and BigQueryToCloudStorageOperator) with just a few simple modifications. They can take lists of values instead of single values as parameters, and will then loop on the list to run all the operation in sequence.
This solution trades parallelism and granularity in favour of reducing the number of tasks bundling together multiple operations into a single Airflow task. Using these operators in our example pipeline, we were able to bundle the countries into groups and adjust the trade-off between parallelism and the total number of Airflow tasks. In our case, by using Chains and partitioning our countries into 7 groups, we were able to reduce the number of Airflow tasks by a factor of 35.
Conclusions
The results include better performances in both the single-day and full historical backfill use-cases. Single days run in less than 12 minutes vs. 60 minutes (a 5x improvement). Running the 3-year backfill for our 3 different types of pipeline finish in less than a day instead of an estimated 3 months (90x improvement)! This helps to confirm that the problem was indeed the Airflow per-task overhead.
Of course, this is somewhat expected, as Airflow is not designed to be a real-time system and is really designed for managing larger and more complex pipelines.